Basic Concepts of Machine Learning
什么是机器学习?
机器学习是人工智能的一个分支,从事构建和研究可以从数据中学习的系统。通过算法使计算机能够从数据中学习和改进,而无需显式地进行编程。它的目标是通过训练数据来预测或分类未知数据,从而自动完成某些任务。
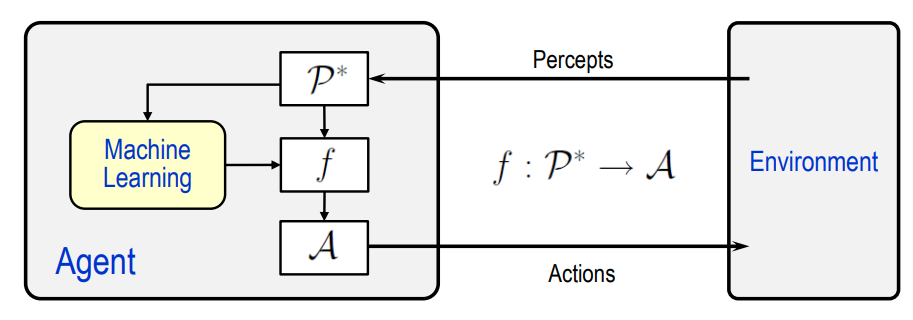
与其他学科的关系
Statistical Learning 统计学习
Pattern Recognition 模式识别
Data Mining 数据挖掘
Computer Vision 计算机视觉
两种通用的学习类型
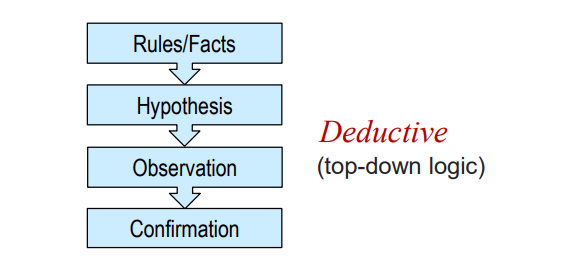
归纳学习:从特定的训练实例中获得或发现通用的规则或事实
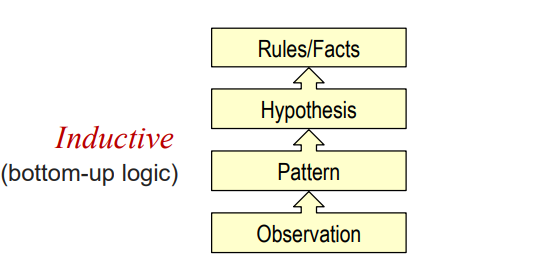
演绎学习:使用一套已知的规则和事实去推导适合该训练数 据的猜测
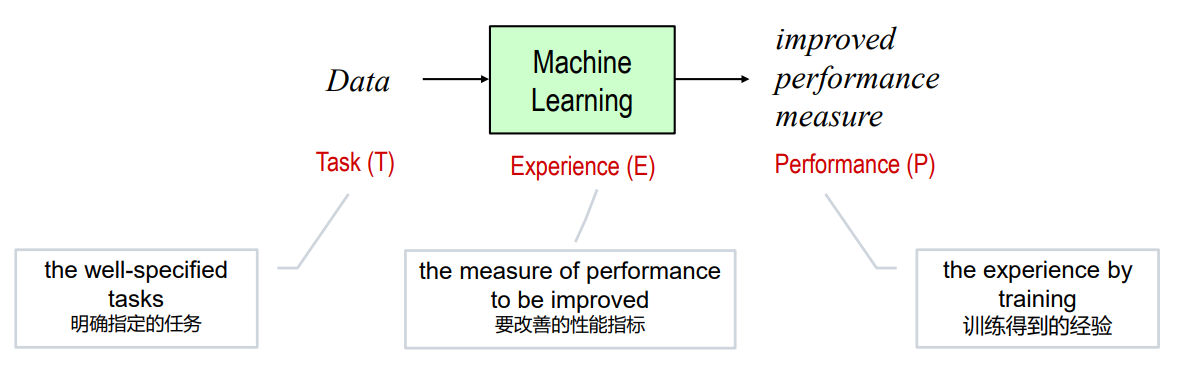
机器学习的形式化定义
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E
监督学习、无监督学习、半监督学习和强化学习 监督学习是指给定带标签的训练数据,通过算法来学习预测未知数据的标签。 无监督学习是指在没有标签的情况下,从数据中学习其结构和模式。 半监督学习是介于监督学习和无监督学习之间,它利用带有标签的和未标记的数据来进行学习。 强化学习则是一种学习策略,该策略基于环境的反馈来改善行动决策。 数据预处理 数据预处理是机器学习中非常重要的一步。这个步骤包括清理数据、处理缺失值、标准化数据、数据编码、数据集划分等。
特征工程
特征工程是指从原始数据中提取有用的特征,以便算法能够更好地学习和预测。特征工程包括特征选择、特征提取、特征构建等。
模型选择和评估
选择适合问题的模型是机器学习中非常重要的一步。常用的模型包括线性回归、决策树、随机森林、支持向量机、神经网络等。评估模型的指标包括准确率、精确率、召回率、F1值、ROC曲线和AUC值等。