FFT Implementation
Taichi Implementation
https://github.com/StellarWarp/Taichi-Radix-N-FFT
HLSL Implementation
https://github.com/StellarWarp/Fast-Fourier-Transform-And-Convolution-On-Unity
HLSL Compute Shader
Compute Shader 是一种运行在GPU上的Shader,可以用来进行通用计算,其运行的方式与其他Shader不同,其他Shader是在每个像素上运行,而Compute Shader是在每个线程组上运行,每个线程组中包含多个线程,每个线程组中的线程可以通过GroupThreadID来获取自己的ID。
Compute Shader 程序可以看作是对线程组编程的程序
group shared memory
group shared memory 相当于一个可编程 L1 Cache,可以用来存储线程组中的数据,这样就可以减少对全局内存的访问,从而提高效率
在FFT中,每个线程组只对某一行或某一列的数据进行操作,因此可以将这一行或这一列的数据存储到group shared memory中,这样就可以减少对全局内存的访问
GPU 存储器层级
GPU中的存储器分为 Global Memory、L2 Cache、L1 Cache、Register,其中 Register 是最快的,Global Memory 是最慢的,L1 Cache 与 L2 Cache 位于中间,L1 Cache 与 L2 Cache 的大小都是有限的,因此如果能够将数据存储到 L1 Cache 中,就可以减少对 Global Memory 的访问,从而提高效率
Unity中进行Compute Shader Profile
使用CommandBuffer与ProfilingSampler进行Profile,CommandBuffer中的操作会被记录到Profiler中,ProfilingSampler可以用来标记CommandBuffer中的某一段操作,这样就可以在UnityProfiler中看到这段操作的耗时了
ProfilingSampler profiler = new ProfilingSampler("FFT Operation");
···
CommandBuffer cmd = new CommandBuffer();
cmd.name = "FFT Command Buffer";
...[other operation]...
using (new ProfilingScope(cmd, profiler))
{
...[operation of interest]...
}
...[other operation]...
Graphics.ExecuteCommandBuffer(cmd);
Profile Module 中选择 GPU,即可看到用时
建议在进行测试前重启一次Unity,这样测试时的结果会更加稳定
测试结果
因为单次FFT的执行时间有所波动
为了使得数据更加方便观察,每一帧进行 $20$ 次的 $FFT$ 与 $IFFT$ ,共 $40$ 次 ARGBHalf 四通道($\text{Complex32} \times 2$) 大小 $1024 \times 1024$ 的 $FFT$ 变换,不进行频域信号分离,显卡:NVIDIA GeForce MX450
| 组合 | 总用时(ms) | 拷贝用时(ms) | FFT Shader 用时(ms) | 平均FFT+IFFT用时(ms) | 平均单通道FFT用时(ms) |
|---|---|---|---|---|---|
| 空Shader | 1.150 | 0.420 | 0.730 | 0.037 | 0.005 |
| 仅读写 | 13.114 | 0.410 | 12.704 | 0.635 | 0.079 |
| R2 | 24.037 | 0.409 | 23.628 | 1.181 | 0.148 |
| R4 | 17.974 | 0.425 | 17.549 | 0.877 | 0.110 |
| R8+R2 | 18.433 | 0.420 | 18.013 | 0.901 | 0.113 |
| R16+R4 | 53.338 | 0.407 | 52.931 | 2.647 | 0.331 |
| R4* | 17.431 | 0.408 | 17.023 | 0.851 | 0.106 |
| R8*+R2 | 15.919 | 0.409 | 15.510 | 0.776 | 0.097 |
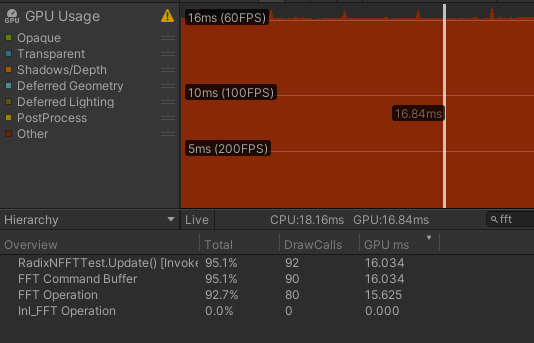
| R16+R4 | 16.034 | 0.409 | 15.625 | 0.781 | 0.098 |
| R32 | 992.514 | 0.552 | 991.962 | 49.598 | 6.200 |
gantt
title Average FFT + IFFT Time (μs)
dateFormat X
axisFormat %s
section Empty
37 : 0, 37
section Read Write
635 : 0, 635
section R2
1181 : 0, 1181
section R4
877 : 0, 877
section R8+R2
901 : 0, 901
section R16+R4
2647 : 0, 1181
section R4*
851 : 0, 851
section R8*+R2
776 : 0, 776
section R16*+R4*
781 : 0, 781
至此已经差不多是优化的尽头了,最佳的R8*+R2组合平均用时 0.776 ms 而仅读写数据就平均需要 0.635 ms,目前的瓶颈是RWTexture与group shared memory间读写的开销
用表现最好$\text{Radix-8} \times 3 + \text{Radix-2}$ 计算,平均每张ARGBHalf大小1024*1024贴图的单次FFT时间为 0.388ms,平均每通道 0.097ms
一个奇怪的现象,如果将
1
2
3
uint k = i / P;
uint p = i % P;
uint kP = k * P;
替换为在2的幂次下的位运算,或将P的值替换为1<<log2_P,这理论上会更快
1
2
3
uint k = i >> log2_P;
uint p = i & (P-1);
uint kP = k << log2_P;
但是,在Radix-4的优化版本中如此替换反而会使得计算时间骤增,这可能与编译器优化有关系。并且,Radix-2中如此替换也没得到性能提升
测试截图
shader空载
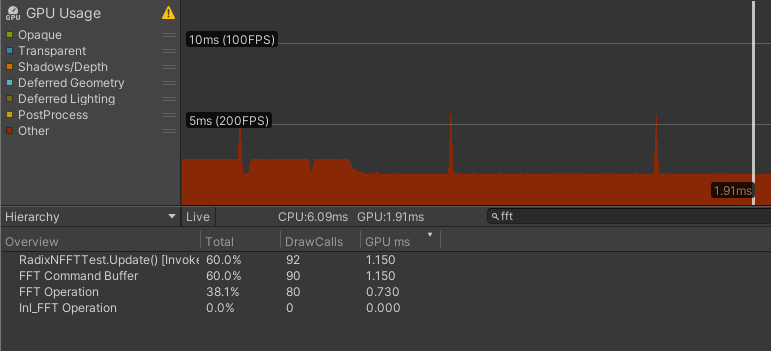
仅读写
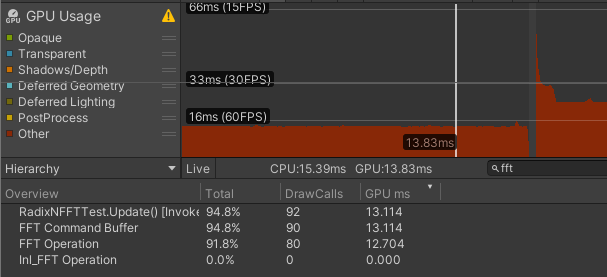
$\text{Radix-2}$
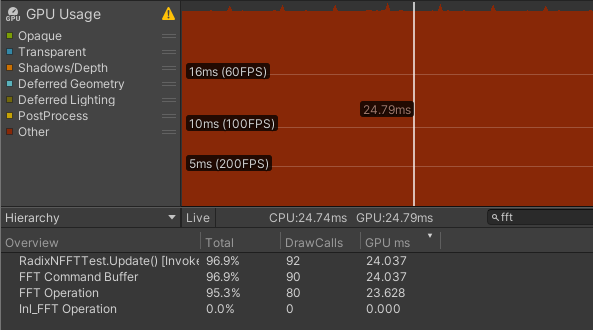
$\text{Radix-4}$ 无细分
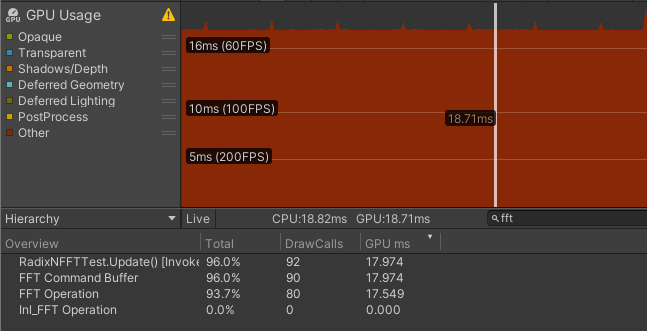
$\text{Radix-8} \times 3 + \text{Radix-2}$ 无细分
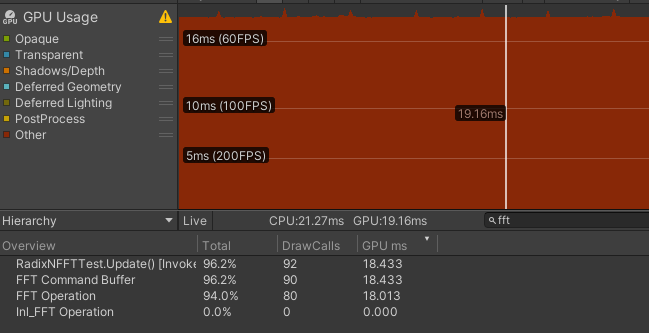
$\text{Radix-16} \times 2 + \text{Radix-4}$ 无细分
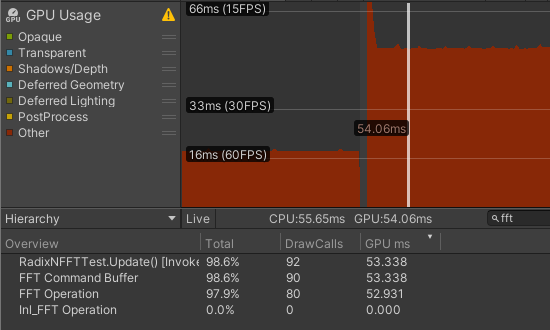
$\text{Radix-4}$ 优化
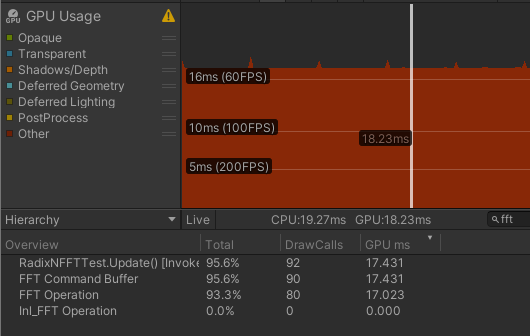
$\text{Radix-8} \times 3 + \text{Radix-2}$ Radix-8 使用3个Radix-2细分
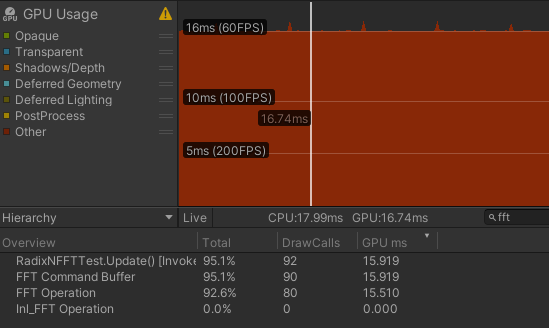
$\text{Radix-16} \times 2 + \text{Radix-4}$